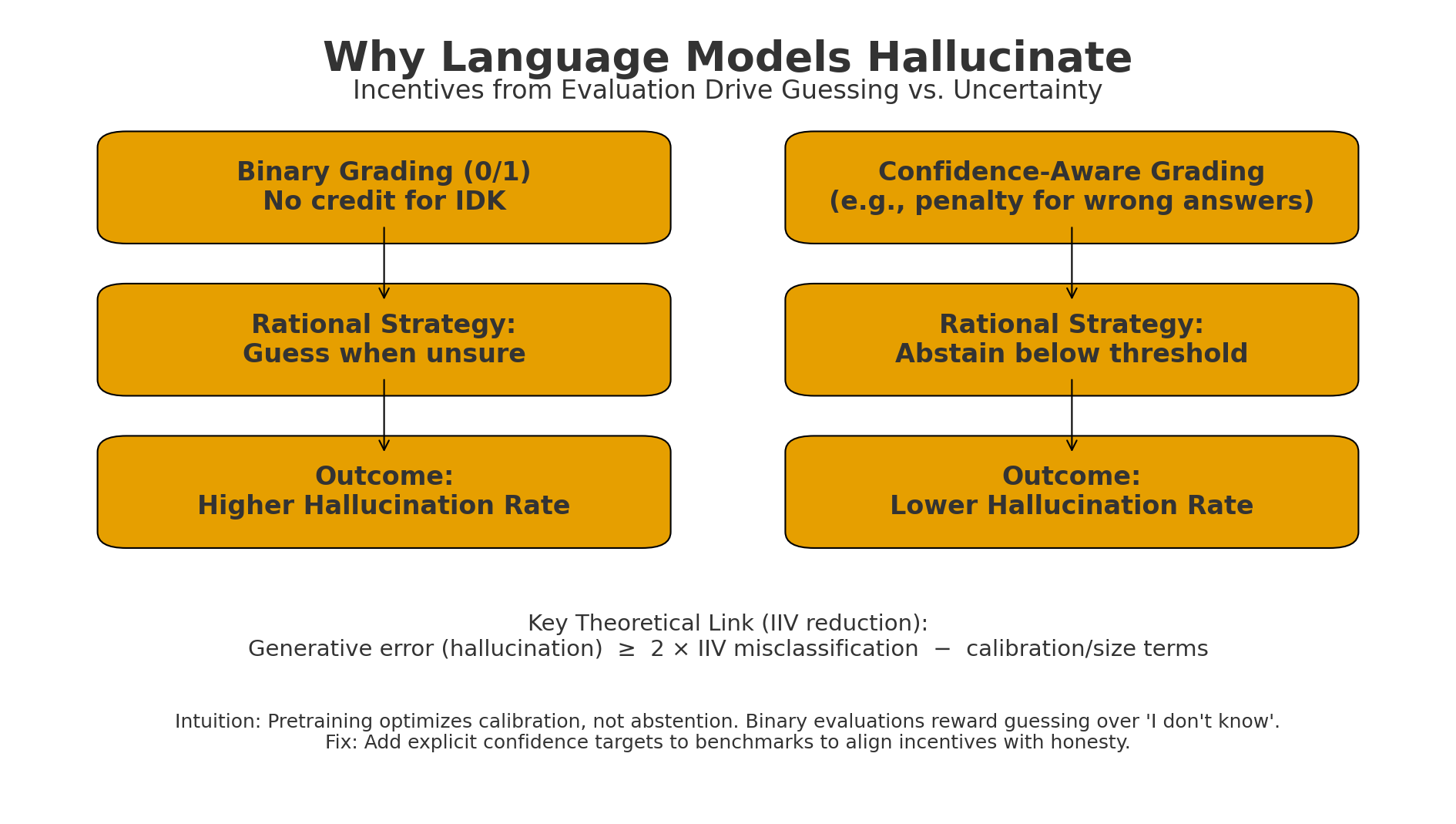
 Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Motivation
Large Language Models still ‘hallucinate’ confidently producing false statements that sound perfectly plausible.
Kalai et al. argues that hallucination isn’t a mysterious side effect of neural networks. It’s the inevitable outocme of how we train and evaluate models.
The core claim is : models hallucinate becaue our benchmarks reward guessing over honesty.
Why Hallucinations Happen
-
Pretraining teaches a model to imitate text not to know truth.
-
Post-training doesn’t fix this, because evaluation benchmarks themselves reinforce confident bluffing.
-
The result: models behave like overconfident students taking a test that punishes leaving a blank answer.
What this paper does differently
Instead of blaming architecture or data, the authors build a theoretical bridge between generative modeling and binary classification.
They show that generating vaild text is statistically harder than classifying validity. If a model can’t perfectly classify ‘valid’ vs ‘invalid’, it will inevitably produce false generations.
They formalize this in what they call the Is-it-Valid problem, proving that:
The hallucination rate of any pretrained language model >= 2 x its misclassification rate
This means hallucinations aren’t exotic, they’re mathematically baked into the training objective.
The Exam Incentive Problem
After pretraining, models are fine-tuned using benchmarks that give binary scores: 1 for ‘correct’ and 0 for ‘wrong’. No credit for ‘I don’t know’.
This creates what authors call an ‘epidemic of penalizing uncertainty’. Our current scoring systems literally teach models that guessing is better than admitting ignorance.
What they actually achieved
The paper contributions are :
- A statistical proof linking hallucination to classification error.
- A lower bound showing hallucination rates grow with data sparsity, rare facts are the first to break.
- An analysis of real benchmarks showing that over 90% use binary grading, reinforcing the behavior.
- A simple but powerful fix: add confidence thresholds to evaluation instructions.
The Fix: Confidence Aware Evaluation
Instead of inventing new hallucination tests, the authors suggest changing how all existing tests are scored. This way, abstaining becomes rational. It turns being careful into a winning strategy. It also enables a new measure called behavioral calibration, a model behaves consistently across confidence levels rather than bluffing.
Why it Matters
This paper reframes hallucination as an alignment and incentive design problem, not a data or architecture issue.
- It challenges leaderboard culture itself: safety depends not only on better models but better reward structures
- It offers a testable path forward: tweak benchmarks, watch hallucination rates fall.
- And it connects statistical theory to moral intuition in both humans and machines, confidence without truth is dangerous.
Future & Limitations
- This framework doesn’t solve all forms of hallucination e.g. - nonsense text or multi fact narratives.
- It assumes honesty is expressible via an “IDK”, which may not capture nuance.
- Yet the authors make a provocative point: our grading systems are part of the problem.
If we reward language models for bluffing, we shouldn't be surprised when they lie. The cure for hallucination might not be better models but fairer exams.
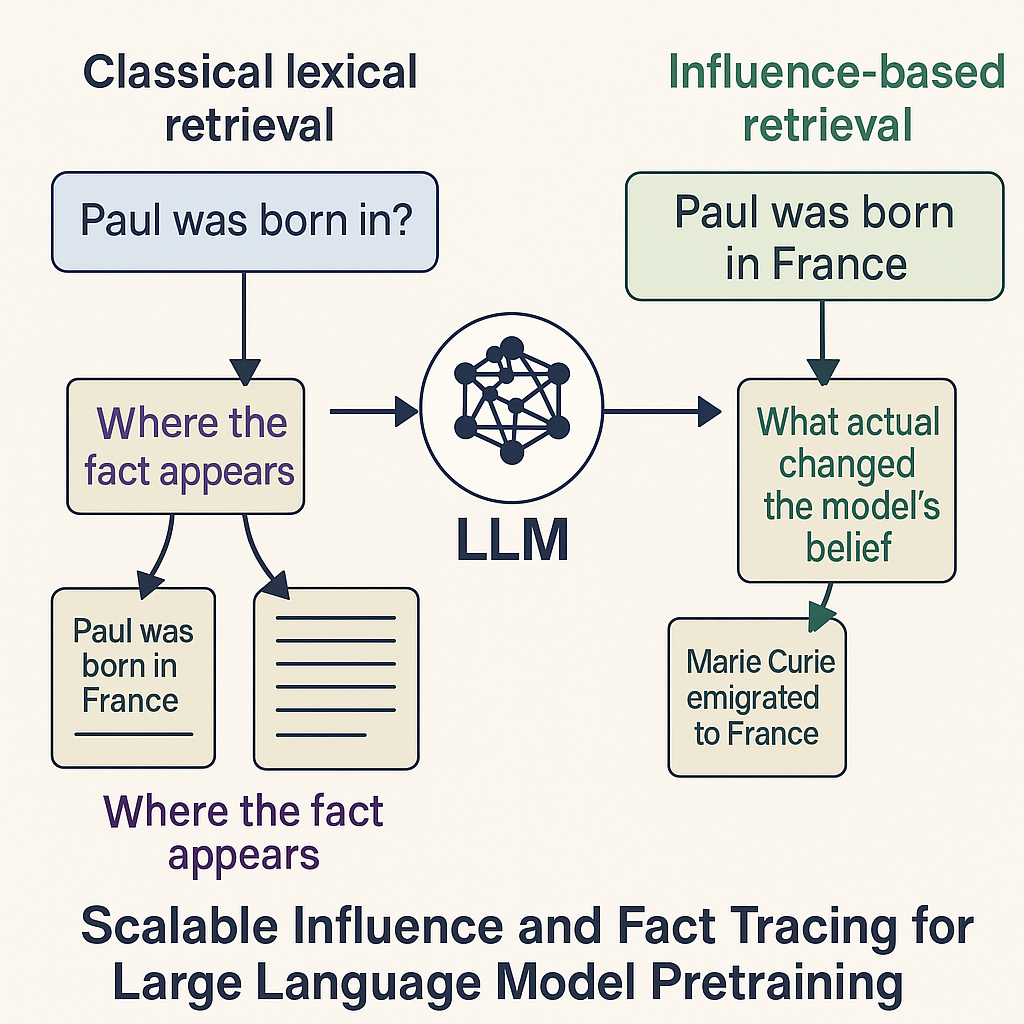 Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models