
What is Data Shapley? Measuring the True Value of Data
Published:
We often focus on model architectures — but what if the most valuable part of your ML system is your data?
Data Shapley assigns a contribution score to each training point, measuring its impact on model performance.
In my ongoing project, I use TreeExplainer and validation-based importance computation to approximate Shapley values efficiently.
Why it matters
Knowing which data points help or hurt your model allows:
- Smarter dataset curation
- Better fairness and robustness
- Insights into which samples actually matter
Imagine debugging a biased model not by tweaking hyperparameters — but by identifying the “toxic” data points.
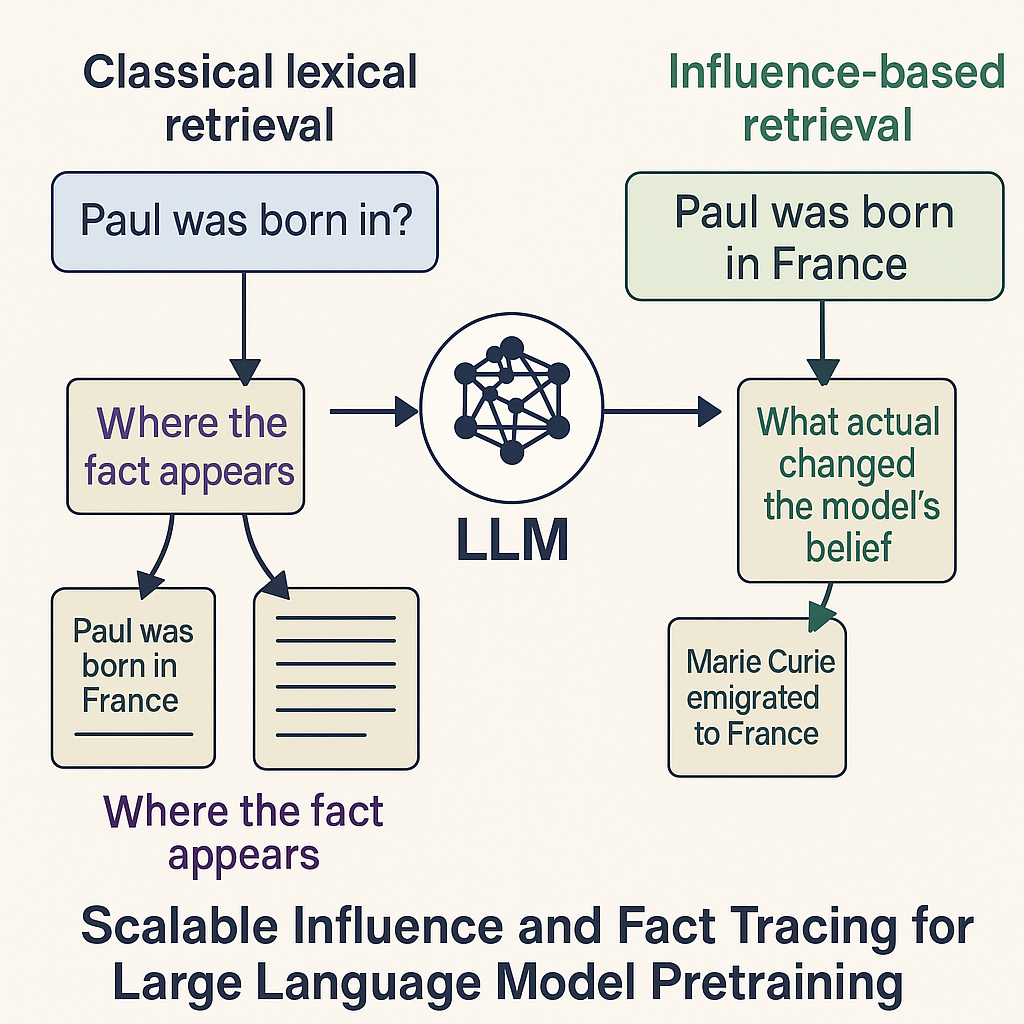 Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models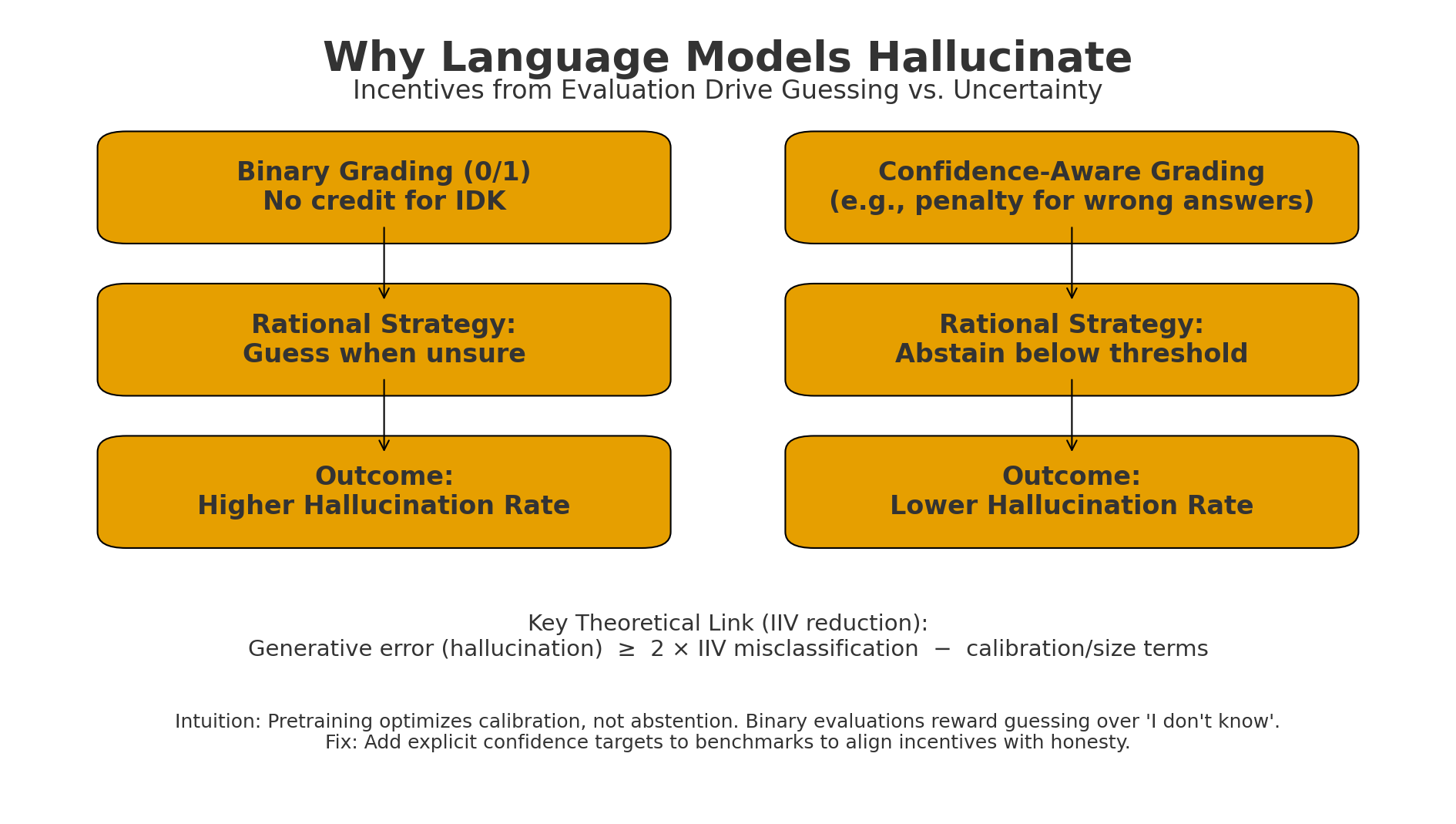 Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.