
Scalable influence and fact tracing for large language models pretraining
Published:
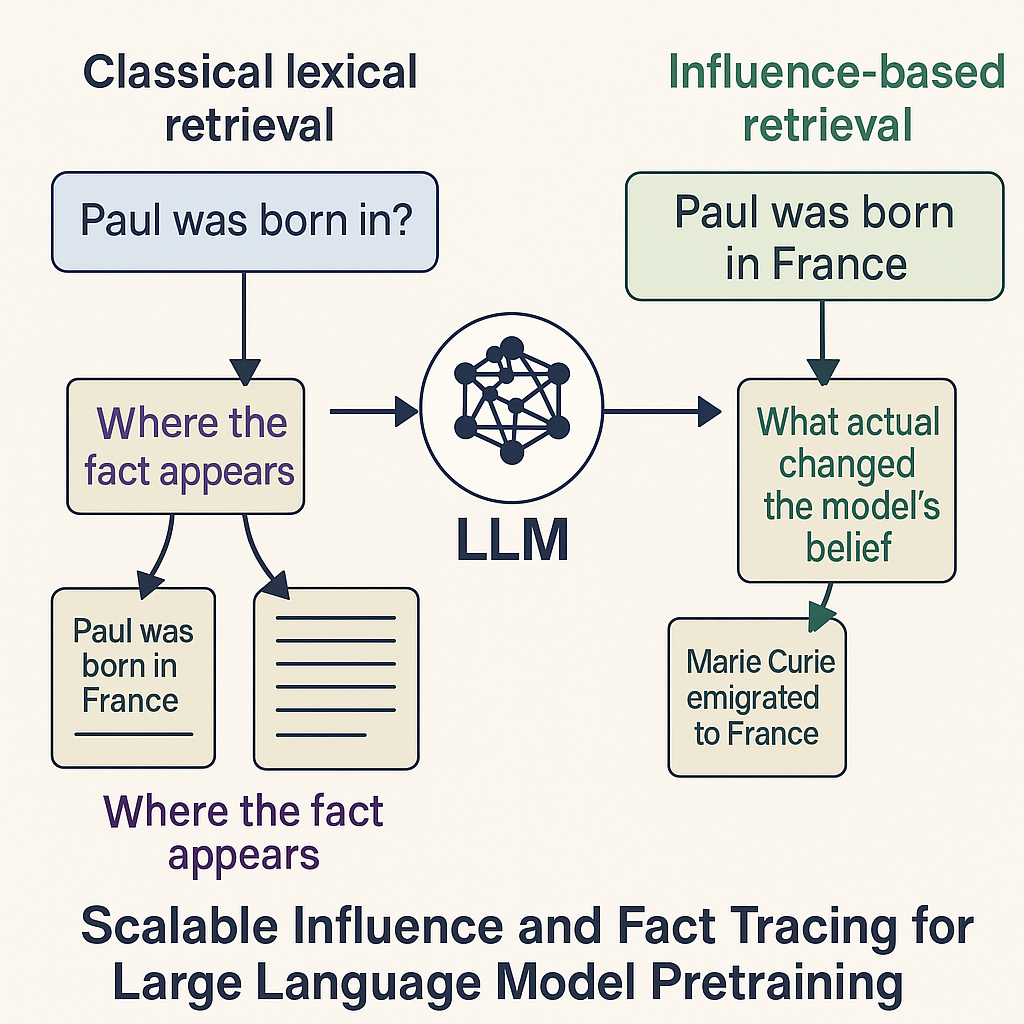 Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Motivation
Large language models can state thousands of facts confidently — but we still cannot reliably trace where those facts came from in the training data.
This is a core challenge for:
- transparency,
- copyright compliance,
- model auditing,
- safety-sensitive deployments.
Training Data Attribution (TDA) tried to answer: “Which training examples most influenced a model’s prediction?”
But until now, all attribution methods either:
- did not scale beyond small models,
- or collapsed into noise when applied to pretraining corpora.
Chang et al. introduce TrackStar, the first method that scales gradient-based influence tracing to 8B-parameter LLMs trained on hundreds of millions of documents.
And what they find is important: Attribution and influence are not the same.
Models rarely learn facts from the sentences that contain them.
Why Fact Tracing Is Hard
- Pretraining mixes millions of subtle statistical patterns.
- Most gradient-based influence methods explode in variance at LLM scale.
- Fact-containing sentences (e.g., “X was born in Y”) are often not the most influential examples.
- Classical retrievers like BM25 excel at string matching, not causal impact.
The result:
Human intuition about “where a model learned something” breaks down in large-scale pretraining.
What This Paper Does Differently
Instead of relying purely on lexical similarity or uncorrected gradients, the authors combine:
- loss gradients over all model parameters,
- optimizer second-moment scaling (Adafactor/Adam-style),
- massive random projections (65k dimensions),
- a mixed Hessian approximation (to remove template noise),
- cosine-normalized influence scoring.
What TrackStar Actually Achieves
The paper demonstrates:
Influence ≠ attribution.
BM25 and Gecko retrieve fact-containing passages better than gradient methods.
But these passages barely shift model predictions under tail-patching.- Influential examples often lack the fact entirely.
They encode:- relational templates,
- entity type priors,
- structural patterns,
- distributional cues.
Influence correlates with lexical attribution only at larger scales.
Bigger models show more alignment between “cause” and “content.”- TrackStar proponents change probabilities >2× more than lexical proponents.
Even ground-truth T-REx fact sentences have weaker causal impact than TrackStar’s retrieved examples.
This reframes what “learning a fact” means in LLMs.
Why Attribution Breaks (and Influence Wins)
Classical retrieval assumes:
If a model predicts “Paris is in France,” it must have learned this from a sentence containing both words.
But TrackStar shows the real story:
- The model may have learned geography from many nearby examples.
- It may rely on name similarity (“Paris Hilton”).
- It may learn from country–capital templates.
- It may rely on broad distributional patterns (“France” is often the completion to “capital of…”).
Influence-based methods capture these hidden causal pathways, not just literal text matches.
Why It Matters
This work provides the strongest evidence yet that:
LLMs rarely memorize facts explicitly.
They assemble answers from distributed patterns.Fact tracing cannot rely on lexical matching alone.
For safety, auditing, and copyright, we need causal influence.Scaling changes attribution behavior.
As models grow, influential examples gradually become more lexical — an emergent alignment.Gradient-based influence can scale.
Even if the engineering cost (87 TB) is enormous, this sets the path for future systems.
Limitations & Open Questions
- TrackStar is expensive: storing projected gradients for C4 still requires ~87 TB.
- Influence estimates depend on linear approximations (gradients), not full retraining.
- Per-token or per-span attribution might be needed to remove document-level noise.
- Hessian mixing is heuristic; no theoretical foundation for λ beyond empirical tuning.
- Influence does not necessarily map to human-understandable explanations.
Still, TrackStar moves the frontier substantially.
A Closing Thought
This paper shifts the conversation from *“Where did this fact appear?”*
to *“What actually shaped the model’s belief?”* — a far more interesting and future-proof question for safety and transparency research.
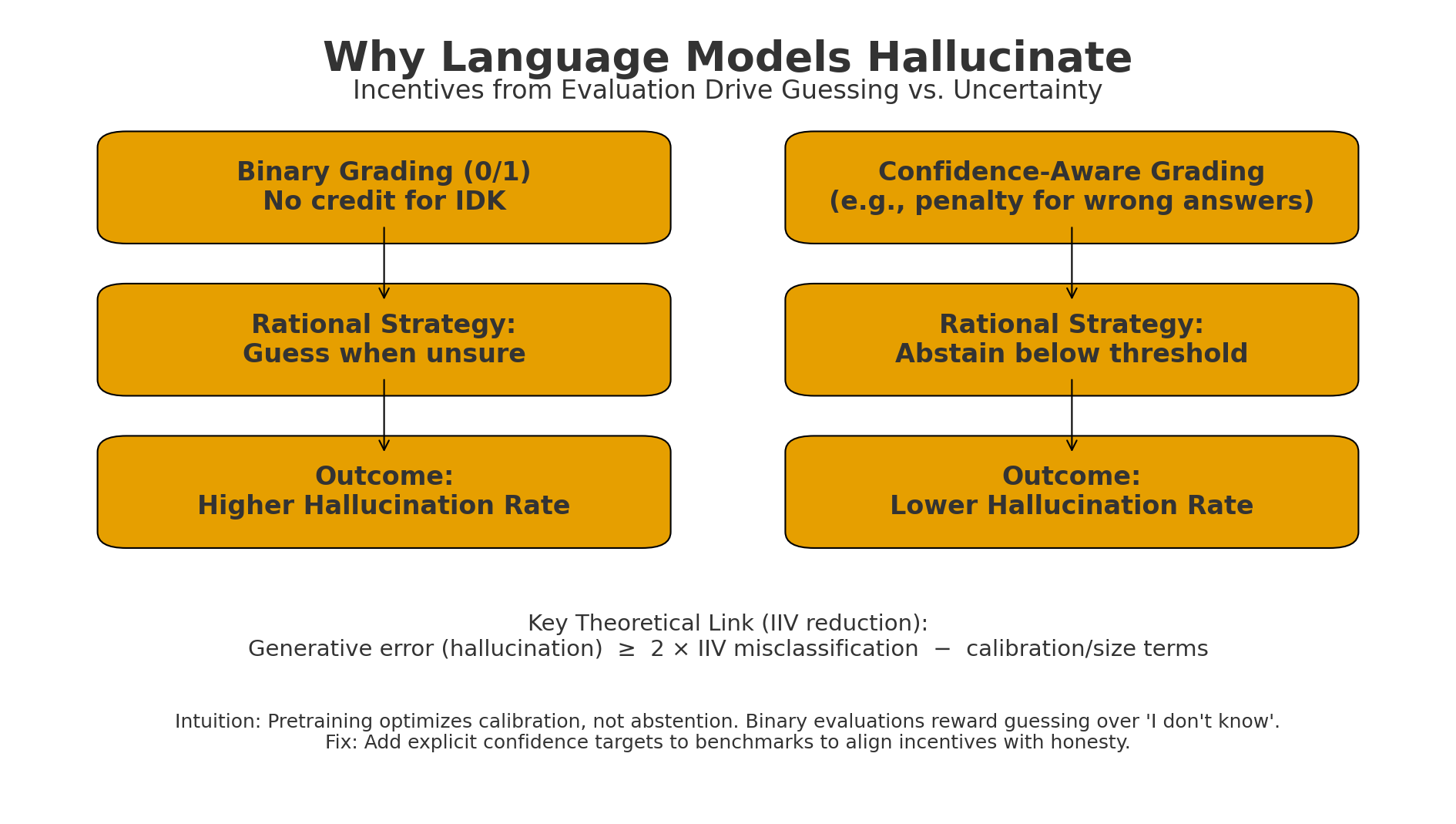 Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.