Scalable influence and fact tracing for large language models pretraining
Published:
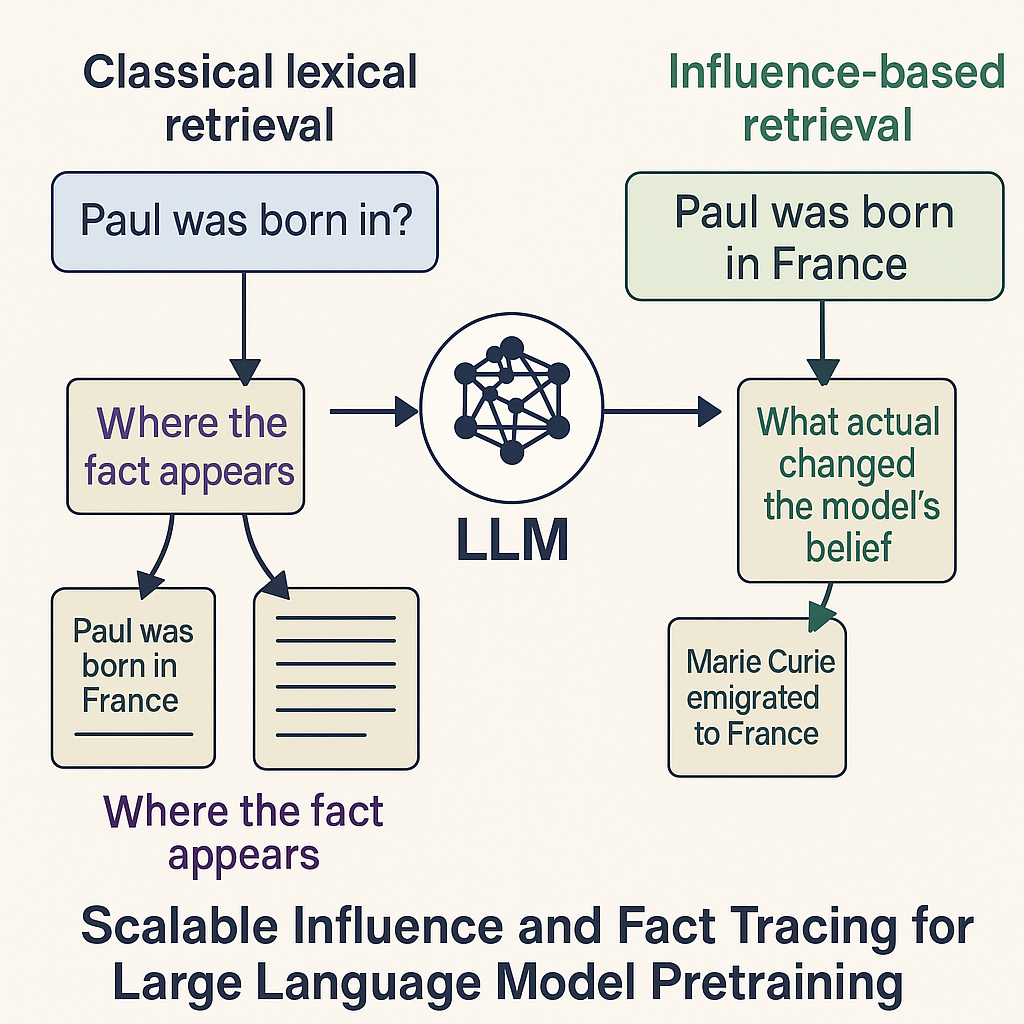 Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models

Published:
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Published:
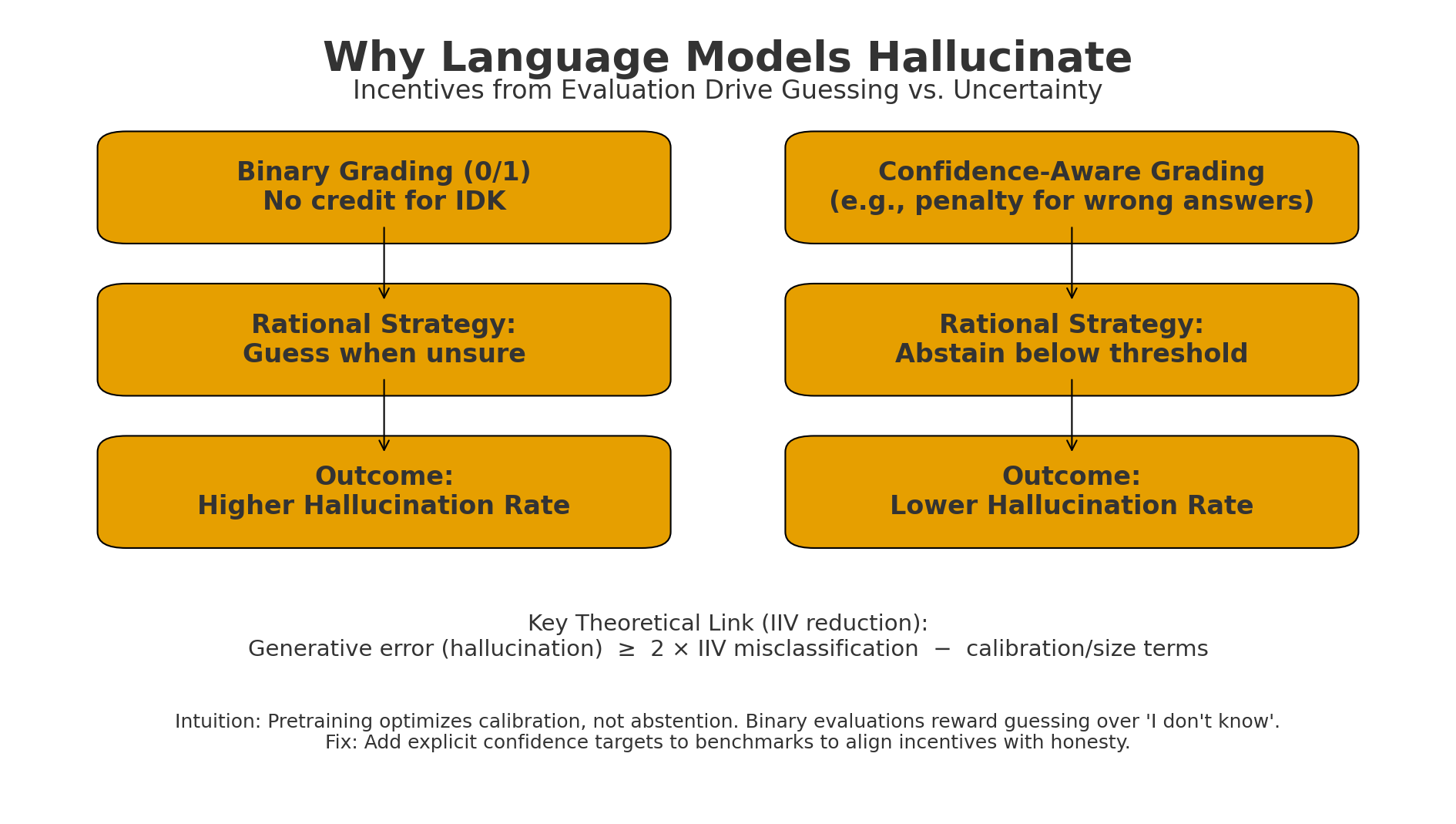 Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Published:
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Published:
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Published:
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Published:
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Published:
How do we collect humanlike motion data for robots without a $100K motion-capture studio?
Published:
Hackathons have been among the best learning experiences of my career.
Published:
We often focus on model architectures — but what if the most valuable part of your ML system is your data?
Data Shapley assigns a contribution score to each training point, measuring its impact on model performance.
Published:
My recent publication in Decision Support Systems (Elsevier, 2025) focuses on temporal knowledge graph-based explainable DSS for cybersecurity.
Published:
We often focus on model architectures — but what if the most valuable part of your ML system is your data?
Data Shapley assigns a contribution score to each training point, measuring its impact on model performance.
Published:
My first research paper, published in Engineering Applications of Artificial Intelligence (2023), proposed SENE — a novel manifold learning technique for analyzing distracted driving.
Published:
Hackathons have been among the best learning experiences of my career.
Published:
How do we collect humanlike motion data for robots without a $100K motion-capture studio?
Published:
My recent publication in Decision Support Systems (Elsevier, 2025) focuses on temporal knowledge graph-based explainable DSS for cybersecurity.
Published:
Hackathons have been among the best learning experiences of my career.
Published:
Books have shaped how I approach ML — not just as a technical field, but as a way of thinking.
Published:
We often focus on model architectures — but what if the most valuable part of your ML system is your data?
Data Shapley assigns a contribution score to each training point, measuring its impact on model performance.
Published:
My first research paper, published in Engineering Applications of Artificial Intelligence (2023), proposed SENE — a novel manifold learning technique for analyzing distracted driving.
Published:
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Published:
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Published:
Books have shaped how I approach ML — not just as a technical field, but as a way of thinking.
Published:
Books have shaped how I approach ML — not just as a technical field, but as a way of thinking.
Published:
My recent publication in Decision Support Systems (Elsevier, 2025) focuses on temporal knowledge graph-based explainable DSS for cybersecurity.
Published:
My first research paper, published in Engineering Applications of Artificial Intelligence (2023), proposed SENE — a novel manifold learning technique for analyzing distracted driving.
Published:
Figure: Difference between the classical lexical retrieval and the influence based retrieval for large language models
Published:
Figure: Binary grading makes “guess when unsure” optimal → higher hallucinations.
Confidence-aware grading (penalize wrong answers; allow IDK) makes abstention rational → lower hallucinations.
Published:
How do we collect humanlike motion data for robots without a $100K motion-capture studio?